
- Aug 15, 2025
The Five Enemies of Scalability
The enemies of scalability are the features of web applications that make it difficult to scale past the user loads they support.
What looks normal under a small user load may be the enemy when the load increases. That’s the reason it is hard to discover scalability issues at the beginning. Let’s go through them slowly one after the other.
Our First Enemy: Bottleneck
It’s a single component in your web application that all the communication must pass through. Bottlenecks are easy to create because they are natural points of communication between the layers in our architecture.
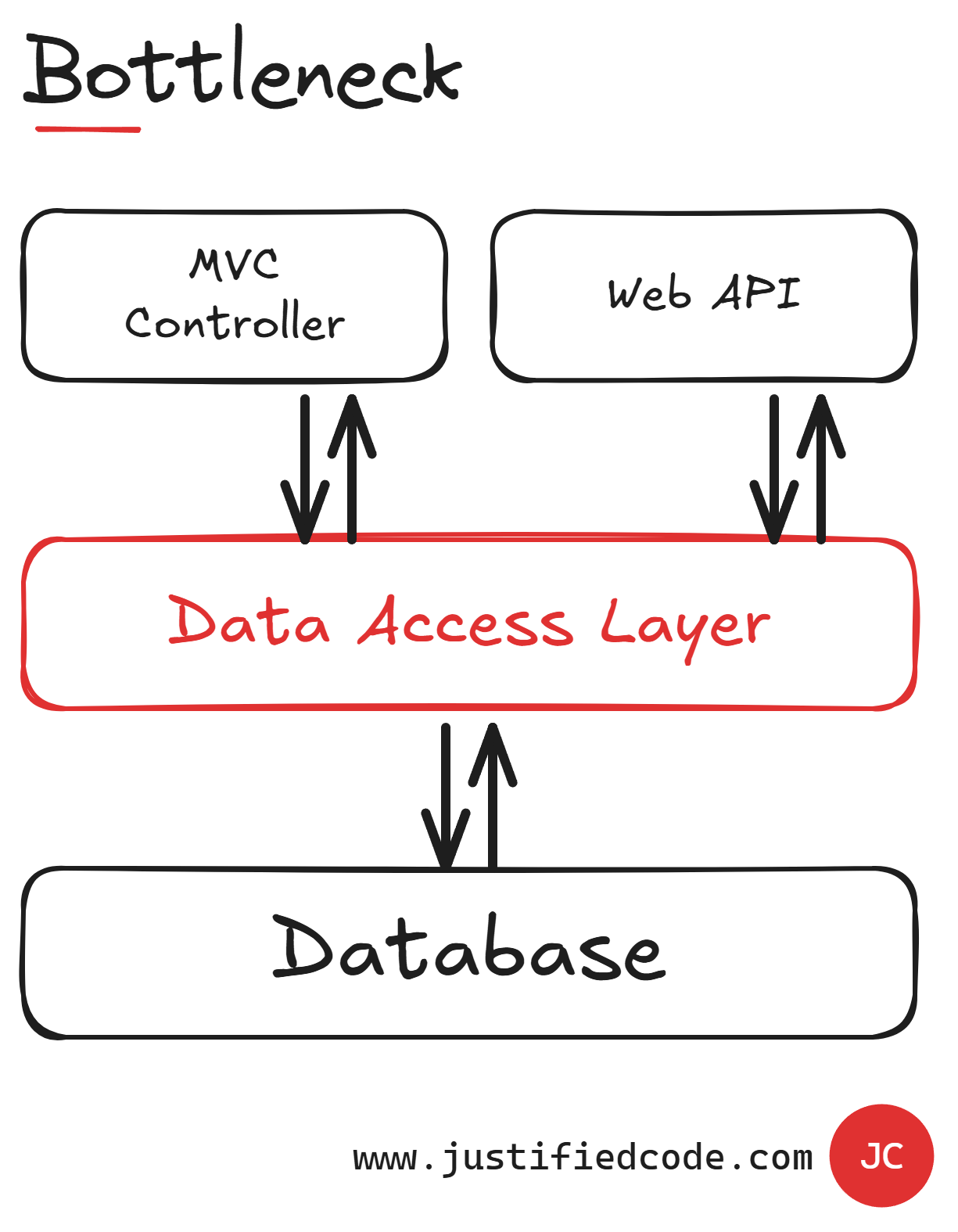
Usually, there is a data access layer in almost any application. If this layer is centralized, all the communication to and from the database passes through it.
This introduces two main problems.
It puts a limit to the communication flow in the application, as it can't accommodate more requests than the bottleneck allows.
It's very easy for a bottleneck to become a single point of failure. More of that below.
Our Second Enemy: Single Source of Truth
The database of our back-end acts as a specialized bottleneck called a single source of truth. Actually, this enemy is more dangerous than the first one.
For example, we can address the data access layer bottleneck by running more applications in a distributed fashion as you can see below, but since they go all the way to a single database, then we still have a single source of truth.
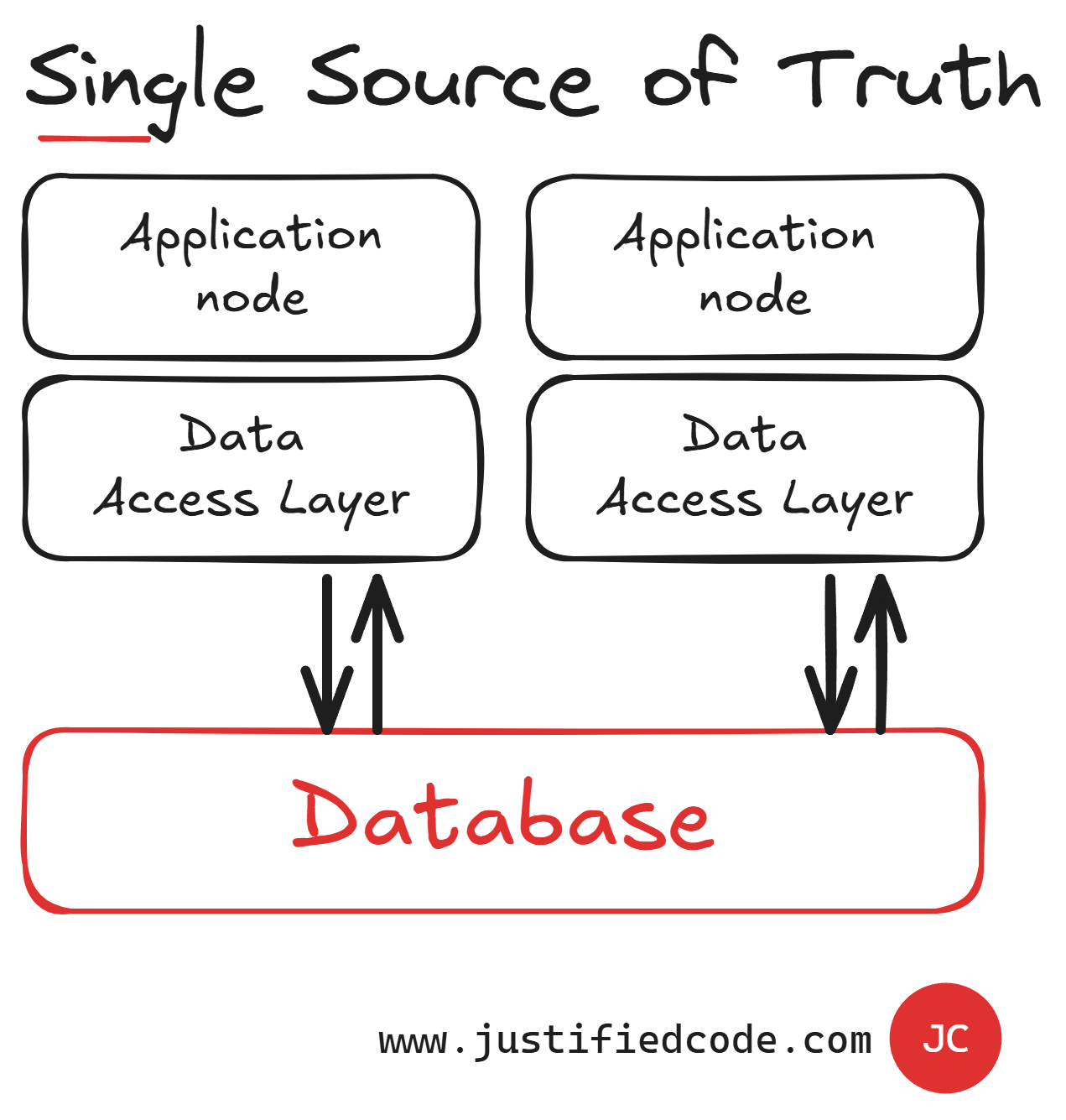
A single source of truth limits the number of requests per second we can get. Also, having a sole source of data makes our application vulnerable to locking, as it serves all the data operations, even if they are just reads and not updates.
Unless we do something with the default design of a single storage, we cannot scale past it.
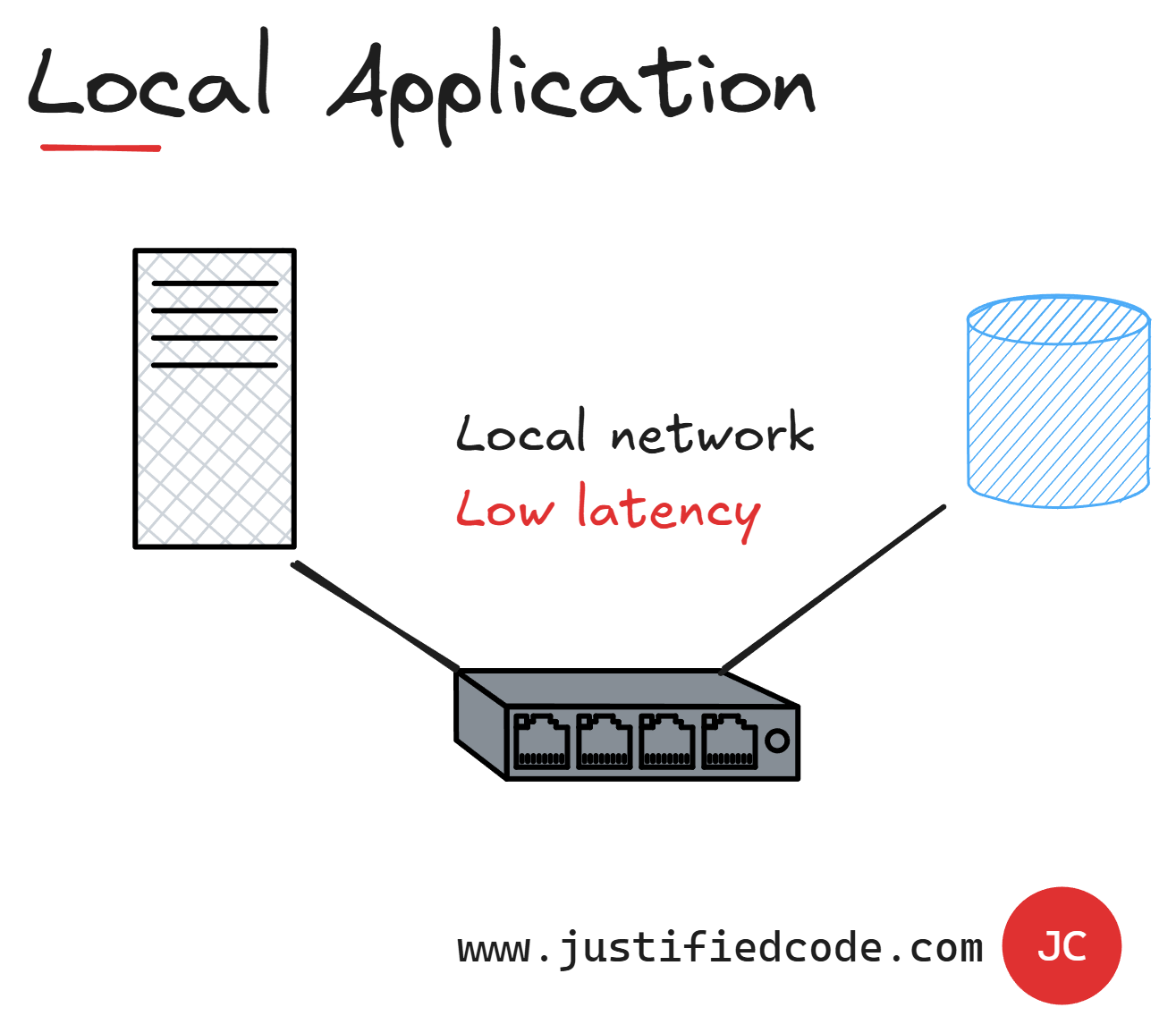
Our Third Enemy: Roundtrips and Latency
Latency is the time delay between sending a request and receiving the first byte of data in return. Consider a remote server: the network delay when contacting it adds to latency. Even if the system on the other side is fast, latency from traveling across a network can slow down the perceived response.
The Latency increases as a result of unnecessary roundtrips and communications in our applications. When our application runs in a local network, all the communication is very quick and the latency introduced by the network is almost negligible.
However, when our application runs in the Cloud and is accessed by thousands of users, the latency increases, as there are many network components between the parts of the application.
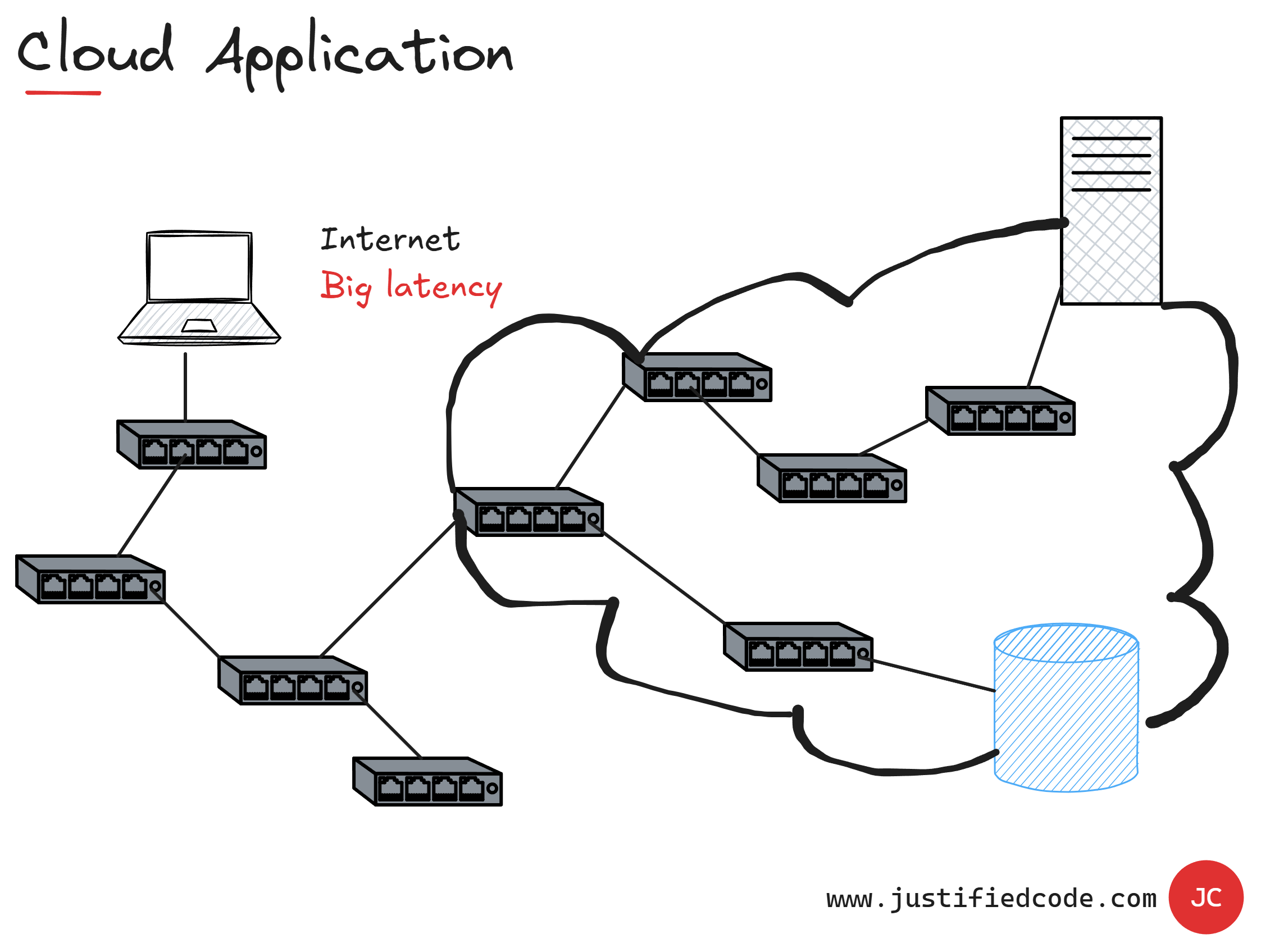
You see from the cloud image, each request has to travel across the internet, to the data center, passing to routers, switches, and other network devices, all of which introduce some delay.
Latency makes our application slower to respond. It makes the calling component blocked until the response is returned from the component that has been called.
Our Fourth Enemy: Blocking Calls
Throughput measures how much data or transactions your system can handle in a given time. Think about it like transferring a file: throughput would be how many megabytes you can move per second. For web applications, throughput might be the number of requests or transactions processed per second.
A web application is by its nature an example of request and response model. One of the pages in the application issues a request to the database and the database responds.
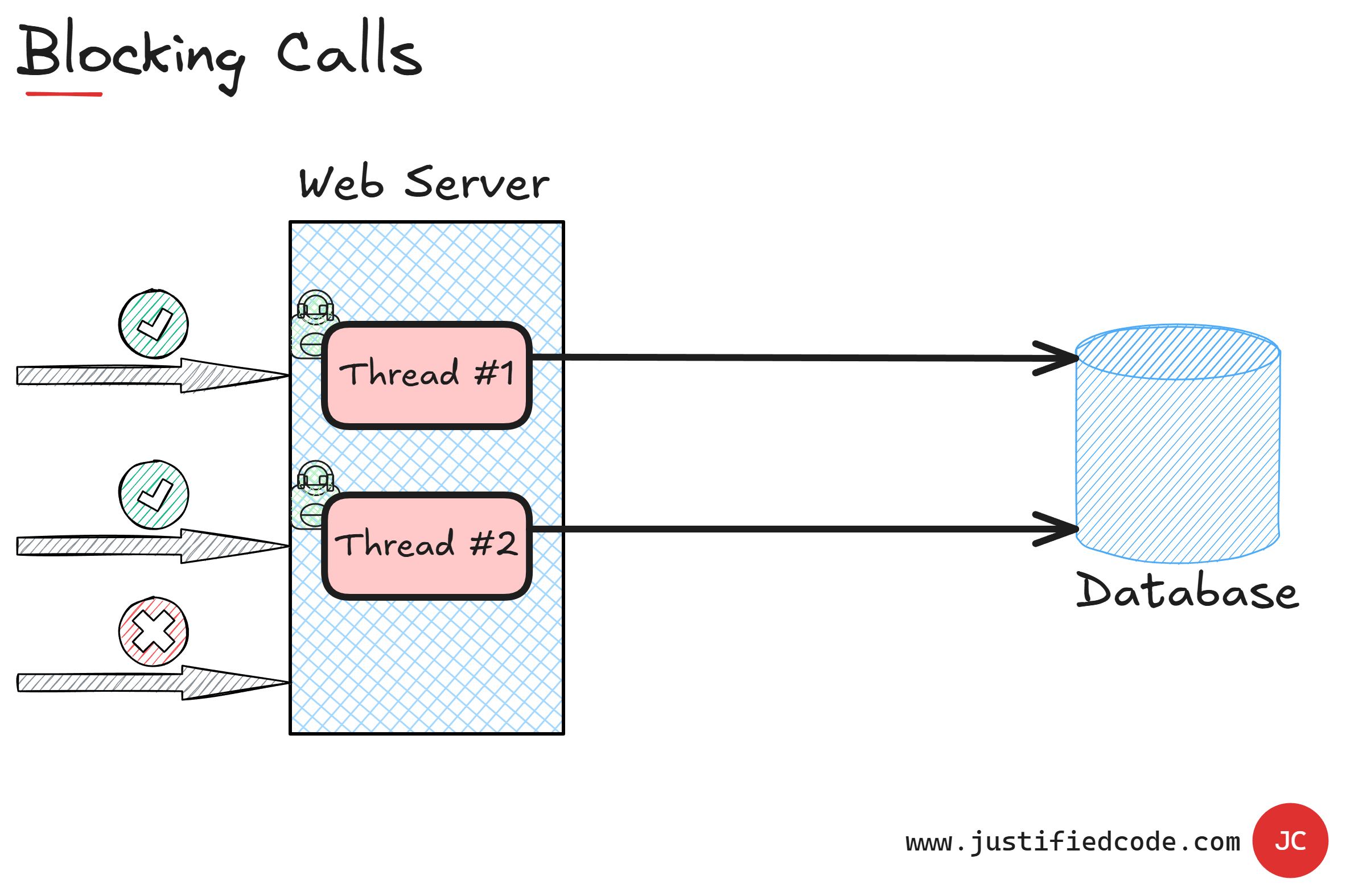
As you can see, during the request and until the response is returned, the calling page and its executing thread are blocked thus not doing anything useful. They just sit idle, waiting for the response to come from the database.
Now, since there is a limited number of threads to make the requests, our application has limited maximum throughput. If all of them are blocked, waiting for the response, our application will make any additional requests wait until one of them is free. Eventually, if the wait is too long, we will begin to see timeouts.
Our Fifth Enemy: Single Point of Failure (SPOF)
A single point of failure or SPOF is a component that if down, breaks the application. In fact, almost every component of our application can act as a single point of failure.
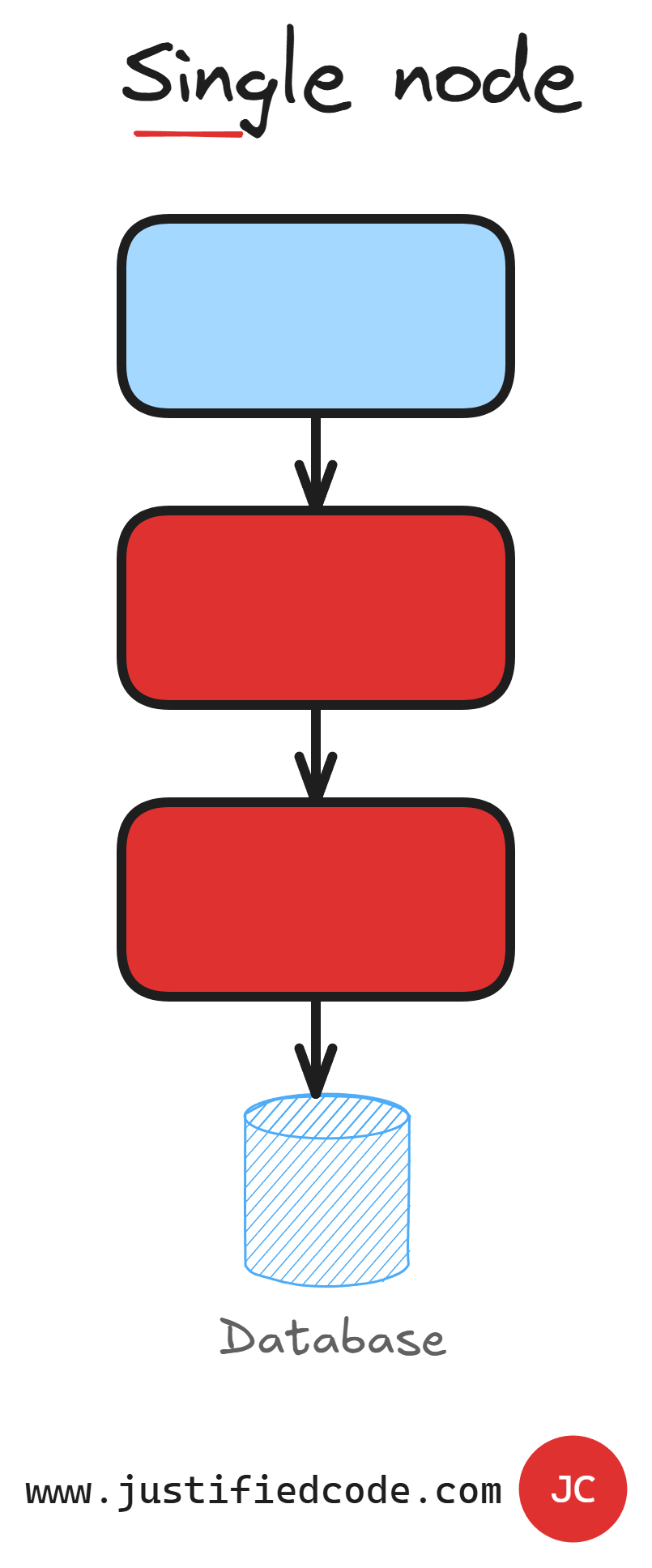
In a single node deployment, see image below, with no load balancing, the entire application is a huge single point of failure.
However, we can spin more nodes with our application as per below image.
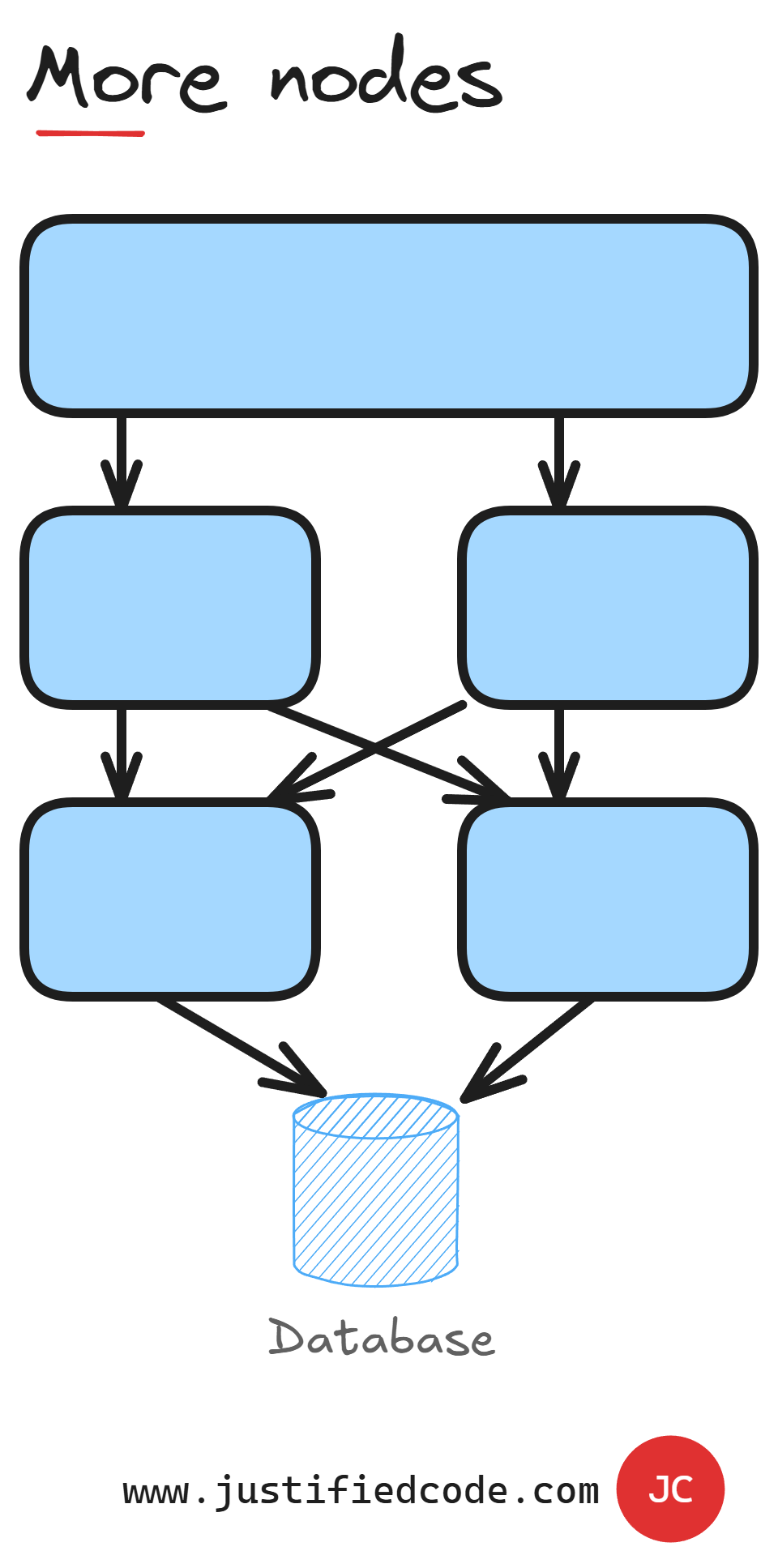
Nevertheless, we will just shift the failure point to the database since all the nodes share the same database. We can also make the database duplicated at least to avoid a single point of failure as per following image.
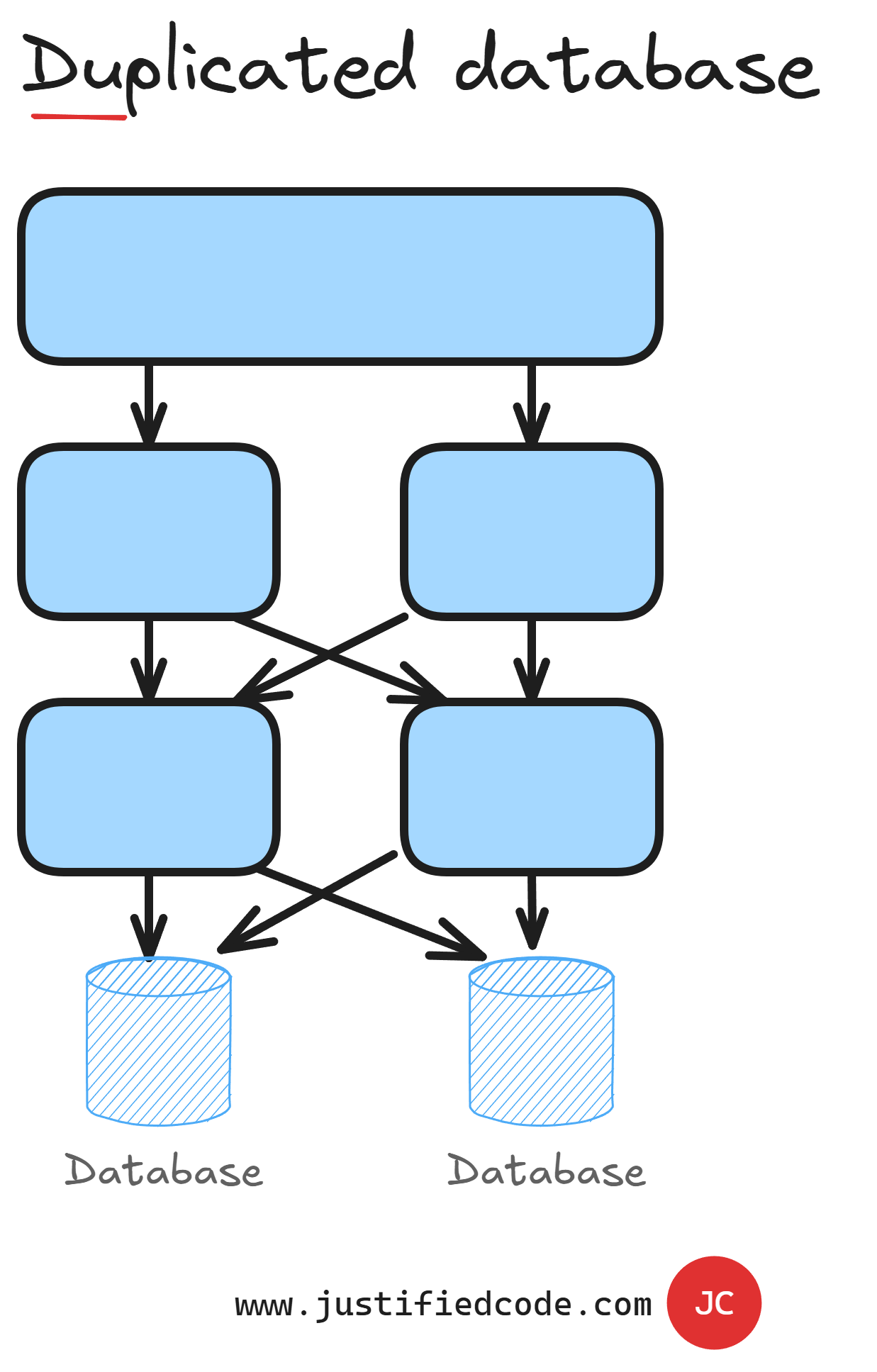
Still, by making more components available, we also introduce a change to our application code. When there is no single instance of a component, it might happen that a series of requests can go through different component instances and they might be processed out of order, more than once or not processed at all.
Next Steps
We have seen how simple architectures have features that are hampering the scalability of the application such as bottlenecks, single point of failure, blocking calls, just to name a few.
We have to redesign our application logic to find a better solution taking the five enemies into account.
How to accomplish that you ask? Good. Head to the Web Applications Scalability course where I break them all down while annotating every neat diagram with a Pencil, sharing raw experience from the field you won’t find anywhere else.