
- Aug 27, 2025
The Five Components of Scalable Applications
After meeting the five enemies of scale, it is time to see the five components that mitigate them thus allow for higher scalability.
Minimizing Storage Locks
The first component of a scalable web application is the reduction in storage locking.
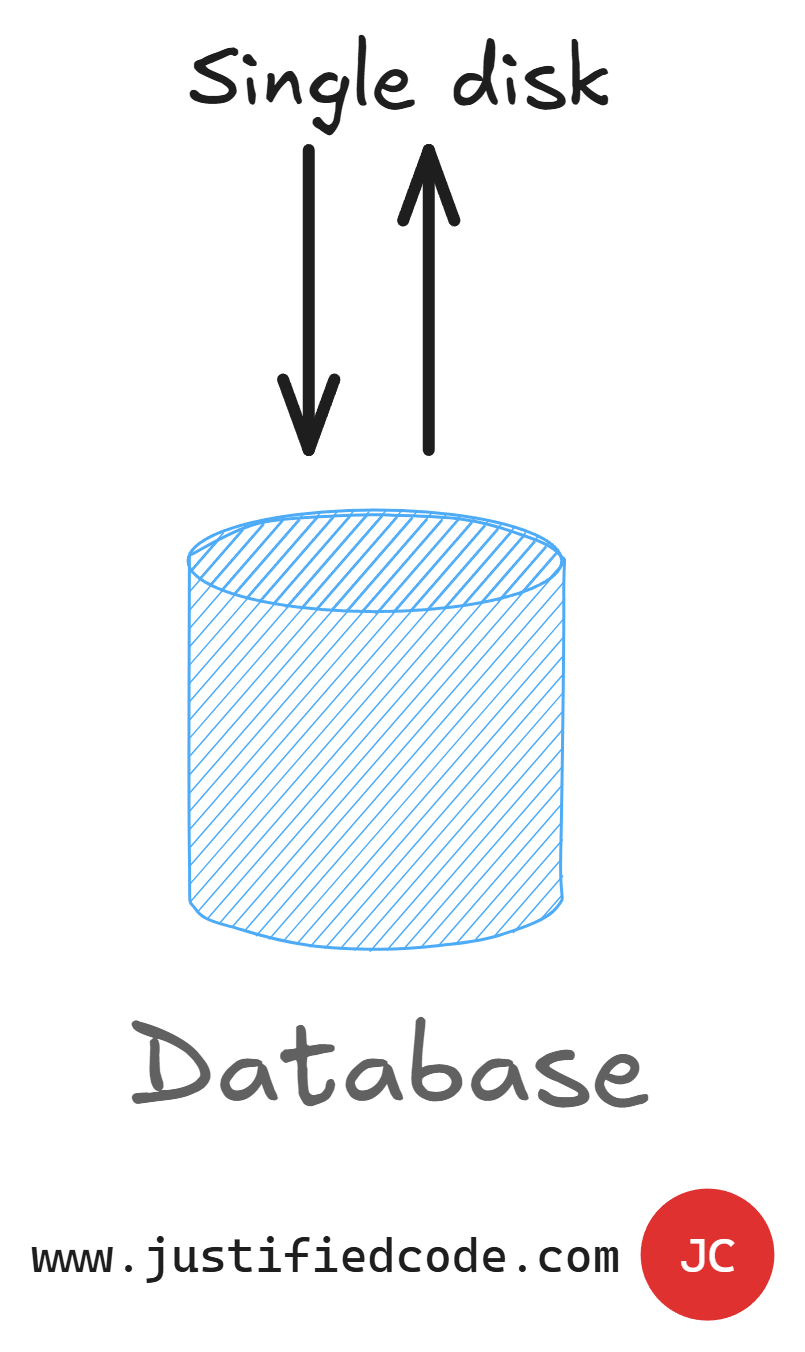
A single point of throughput acts as a bottleneck thus limit our application throughput. We can't go any faster than the data storage. There is no way around it. We can have the most advanced architecture in place, but if our data ends up on a single disk, it will be our ultimate bottleneck.
Here are varied options for minimizing the locking due to the storage of the data in a single point:
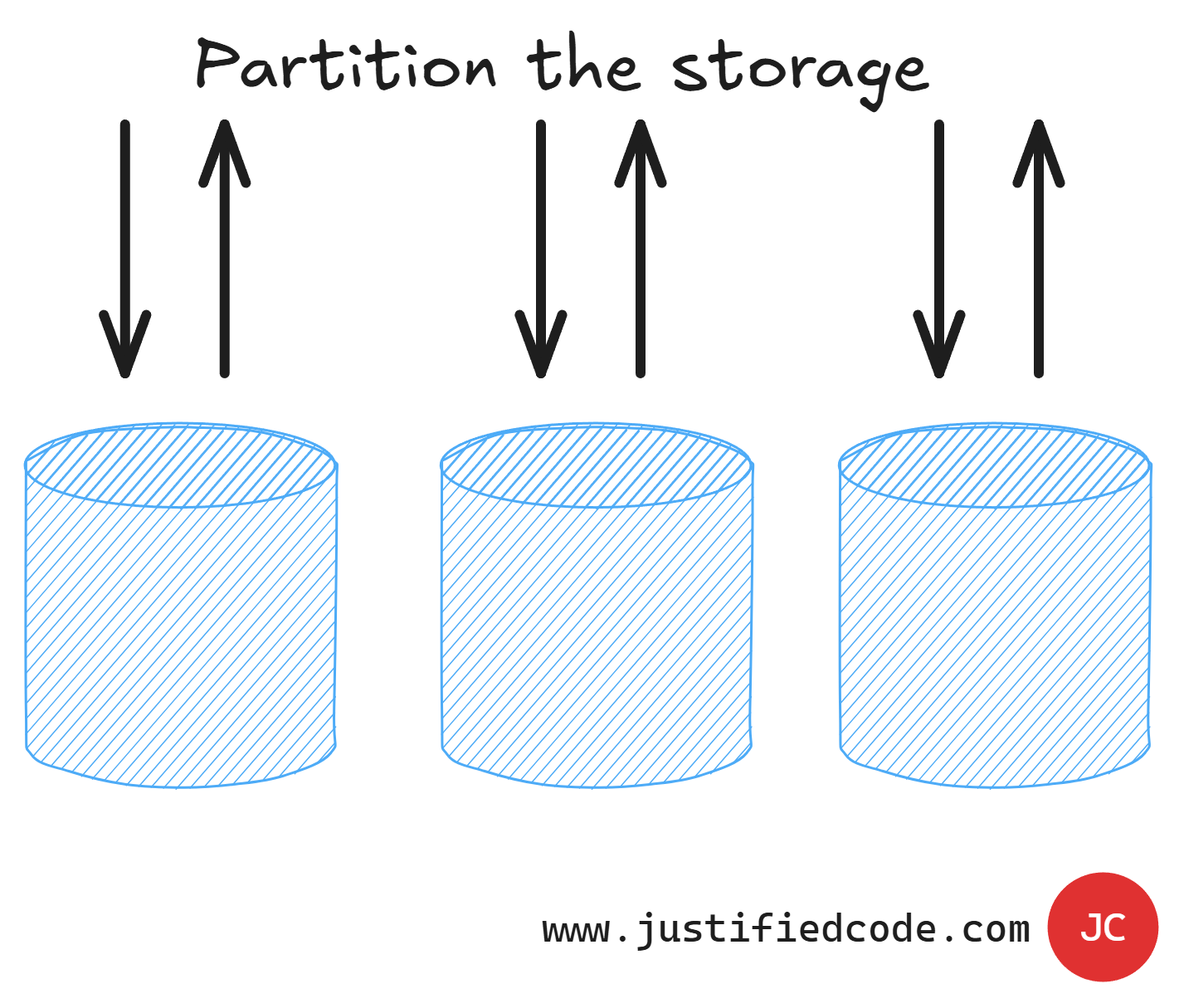
We can split the storage into different parts. This let us get more throughput as there are more components that sum the throughput of all the individual partitions.
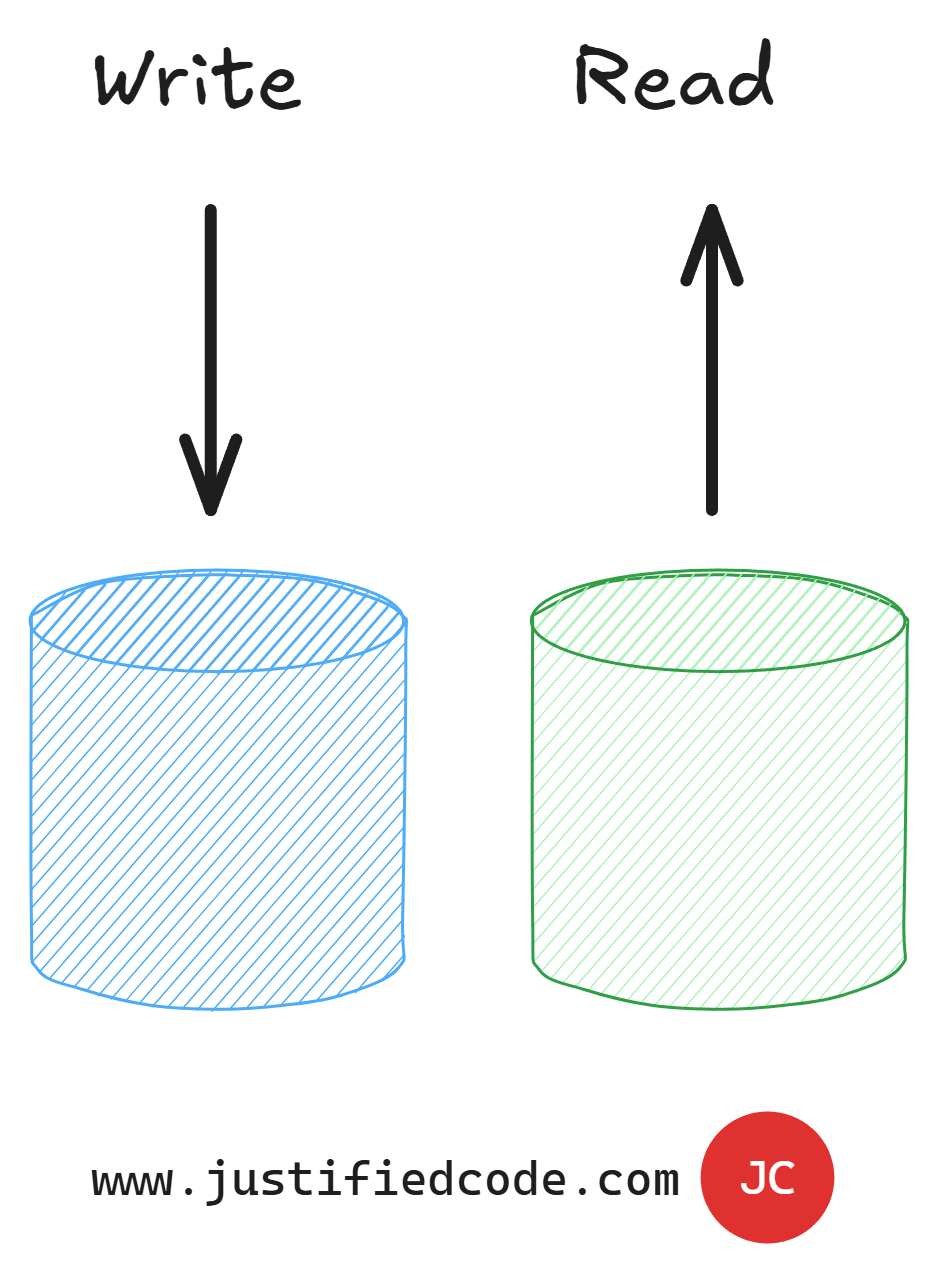
We can also split our database into read and write parts to eliminate the locking due to transaction isolation levels of our database.
We can even replace the relational database with a NoSQL database. However, as we will see in the dedicated article, you always need a relational database specifically for reporting purposes among other concerns.
Caching
The second component of scale is caching. Caching is the cheapest way to reduce unnecessary roundtrips and latency. By copying the data and storing it locally, we basically trade RAM memory for response times.
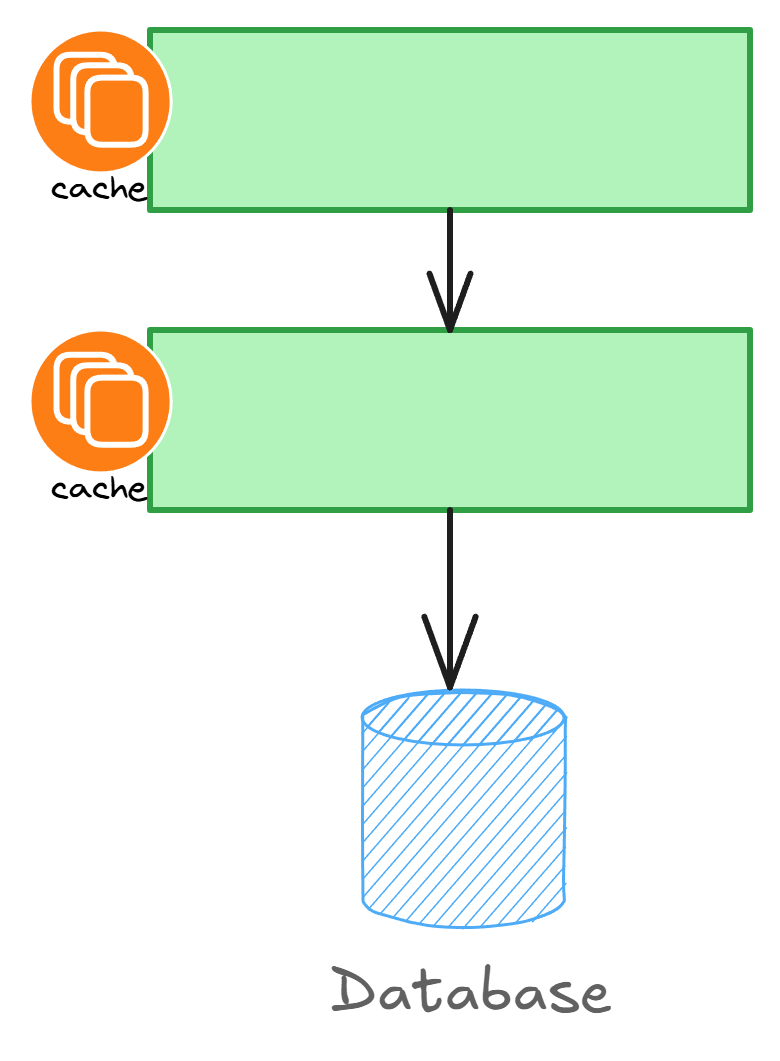
There are several types of caching strategies, but all of them are prone to having stale data. Stale data is a consequence of caching and can be mitigated at least in part by using multiple caching levels and redistributing cache across a dedicated service.
There is no easier way to get more scale than using caching aggressively. Though, it comes with additional problems, but it solves a huge lot of other problems.
Asynchrony
The third component is the use of asynchronous or non-blocking requests.

When an application thread is handling an http request, it is essentially blocked until the response is returned from the backend as per the above image.

However, if the programming language allows us to use asynchronous calls, we can free the thread from idly waiting for the response. This can have enormous impact on the throughput of the application as we are using the existing threads in a much more efficient manner.
The same threads can be reused again and again while still waiting for the existing requests on the backend to respond. This minimizes the useless blocking of the calling threads.
Queueing
Related to the concept of the asynchronous request is a concept of queuing. With async calls we optimize the use of threads, but in the end we still wait for a response.
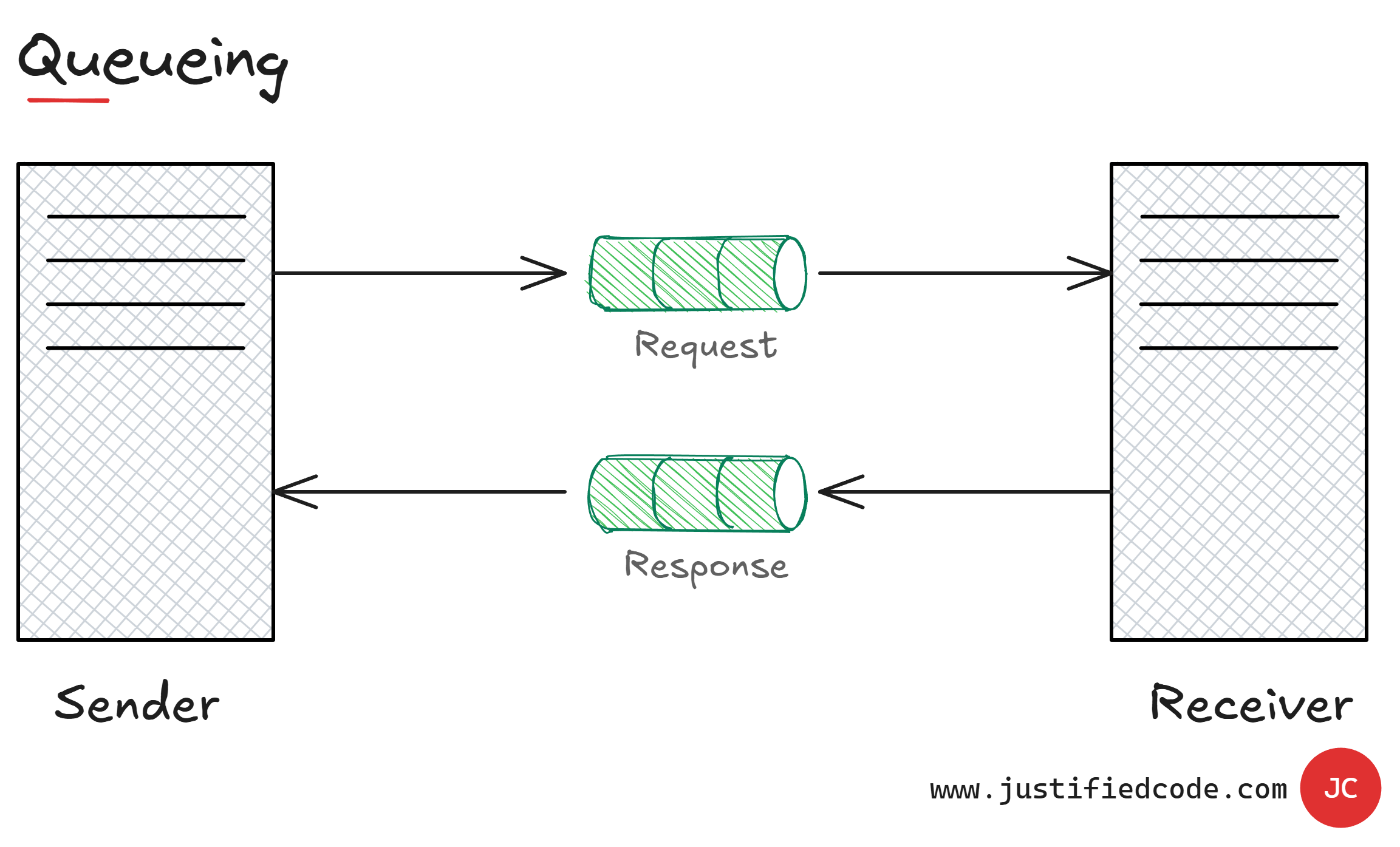
By using queues we can decouple the request response model and just send a message to a queue. The sender is then free to attend other requests. The receiving part is also free to get the messages from the queue and process them at its own pace.
It complicates things a bit, but brings together a whole lot of improvements. We can offload long operations to be processed by other applications and then the results are sent back through another queue.
We can get false tolerance as queue mechanism usually allows for multiple retries if a processing node has failed. We can throttle the requests through the backend and minimize the pressure on it, which comes handy to prevent denial of service or even Distributed DOS attacks.
Redundancy
The last component is redundancy. Having duplicated components all over the board comes in handy.
Strictly speaking, redundancy is mainly used for high availability HA, not for scalability, but they are often used together. Let's clear some thoughts: Scalability is the ability to accommodate increasing loads. Whereas, high availability is the availability to survive the loss of a single component.
Usually, increasing loads put more strain to our application components and ultimately the hardware fails at one point of time. Redundant architecture shields the application from that failure and keeps it running, but usually the response time is somewhat degraded, which is a good trade-off you make.
Adding redundant components has the additional benefit of being able to split the incoming load into different buckets to be processed by different nodes.
However, it has to be taken into account during the architecture as to avoid unpleasant effects of non-idempotent operations. Don't worry. We'll see what this means in the upcoming redundancy dedicated article.
Next Steps
In this article, we have seen how highly scalable applications have common mechanisms to improve the response times and the throughput when facing high user loads.
We've introduced the five components of the scalable applications: reducing storage locks, caching, queuing, asynchrony, and redundancy. Together they make your architecture more performant and resilient. Just don't forget that this all comes with the price of higher complexity. Thus, such decisions must be Justified.
You want in-depth details about them? Good. Head to the Web Applications Scalability course where I break them all down while annotating every neat diagram with a Pencil, sharing raw experience from the field you won’t find anywhere else.