
- Sep 11, 2025
Database Storage Locking - The Fix
After stating the main problem with the way relational databases are implemented in Part 1, it’s time to find a cure. The solution to the read-write complications is simple: one way or another, we have to separate the read source from the write target.
Database Replication
Our first approach for reducing database locking may be database replication. We can copy the master database to a number of other databases called replicas, very frequently.
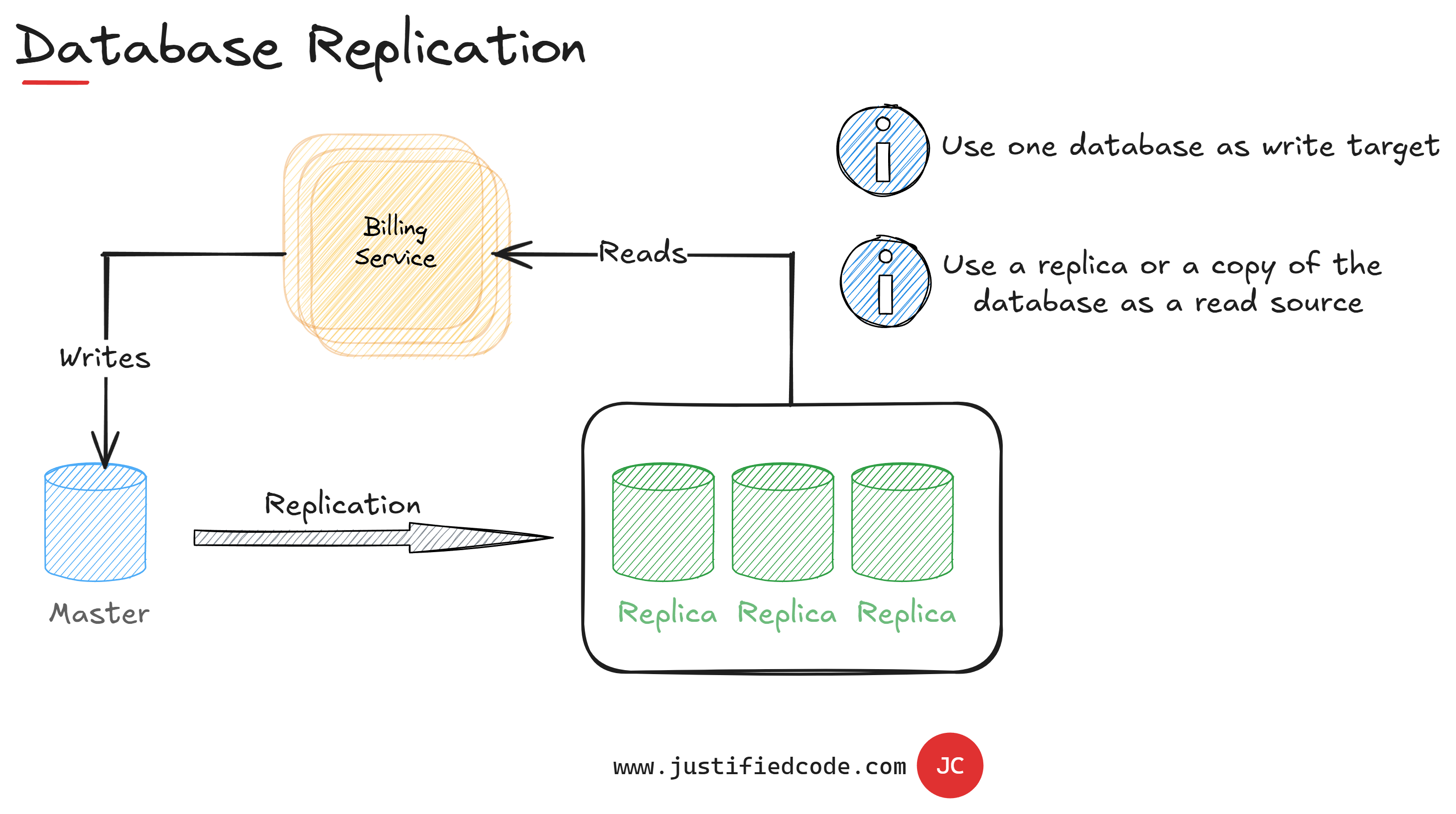
In this case we can use the database replicas to read the data while we direct the write operations to the master database. We still have the same database schema for both reads and writes, but they are not locked as the databases are different.
The only detail is that the replication window has to be short enough to minimize the difference between the fresh data in the master database from the data stored in the replicas. For instance, SQL Server replication can be done using "always on" setup.
Different Database Schema
If we take this idea one step forward, we might use different databases for read and write models of our data. We don't have to share the same schema. We can optimize each one of them for maximum performance.
Usually the write model will be optimized for serial transactions, done one after another, while the read model will be optimized for very quick reads. This particular architecture is more known by the name of CQRS, or command query responsibility segregation.
As its name indicates, it segregates the responsibilities of commands and queries. Commands are concrete objects that encapsulate intents of changing the data in the write model. While the queries are read-only data operations on the read model.
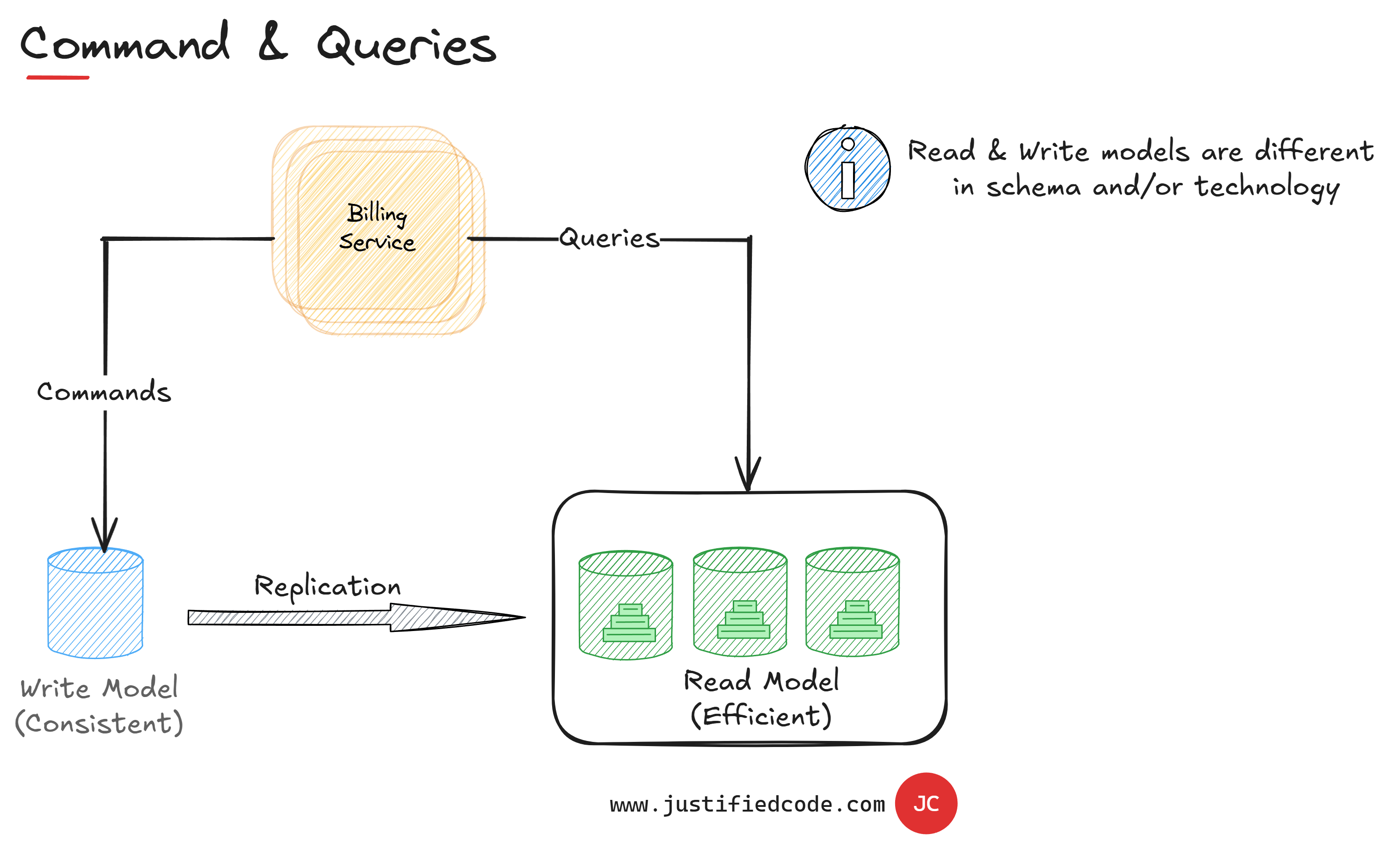
Commands in CQRS are processed one by one. We don't have the performance penalty as there are no reads to be done here. The read model is usually high performant and consists of denormalized data without any relationships.
Huge Data Tables
The third complication with relational databases is that once our data begins to grow the query results begin to be slower. For example, if we have millions of records in our table, every new insert or update will have to make changes to the index in order to ensure quick access to the affected row.
As the index size is functional to table size, manipulating data in huge tables is a slow business. In many cases the data that is stored in these huge tables isn't needed at all.
For instance, our table may contain records that are no longer active. The majority of the users won't even want to see the past records in their interaction with the application, but if our active records are stored together with the past records, we'll have to bear with them even if they are just dead weight to our live system data.
Partitioning or Sharding
The solution to this huge tables problem is called Partitioning or Sharding. It basically means splitting the table horizontally and storing each part of the table in a separate database section or shard.
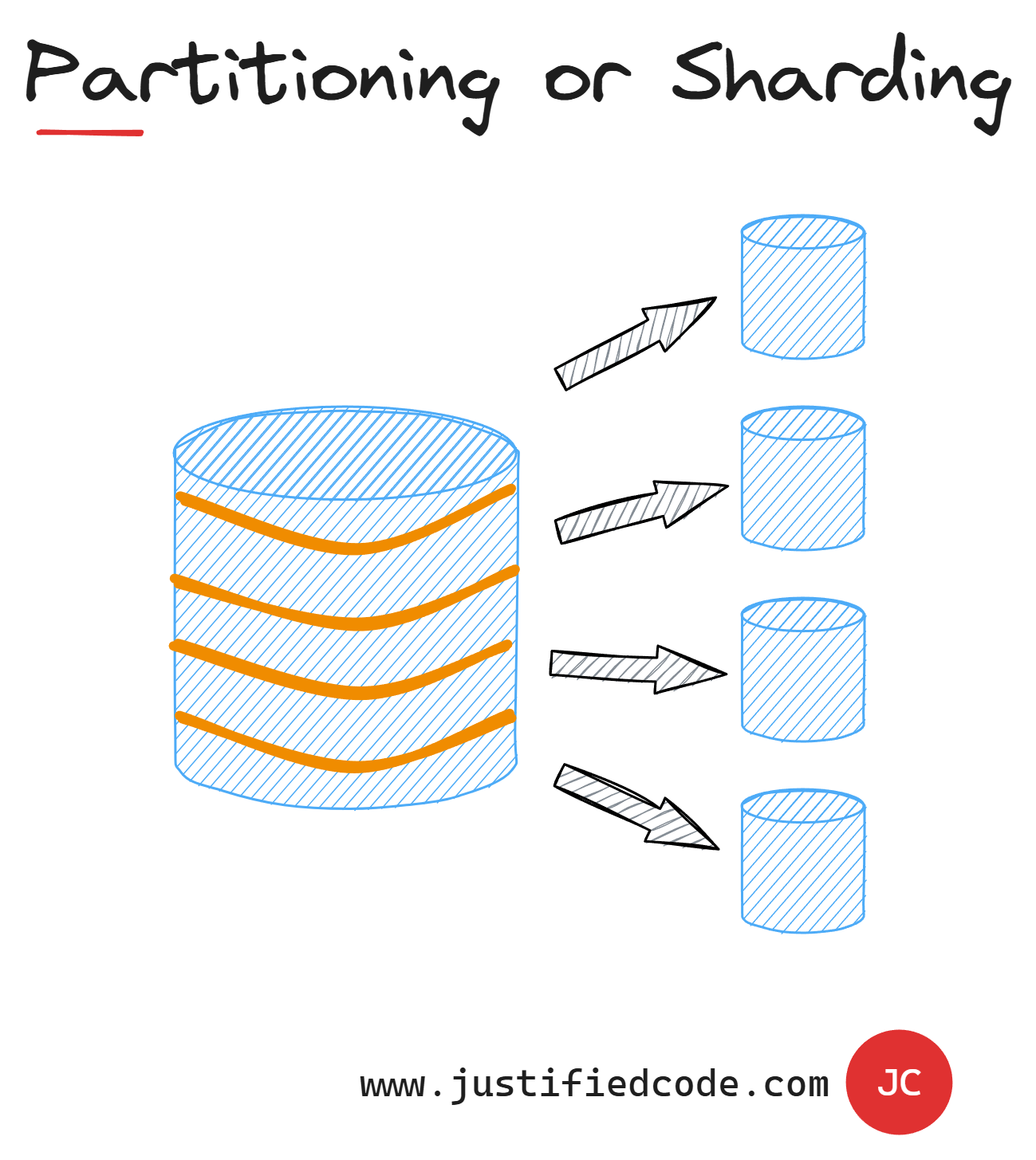
This is done according to a value in a table, we call "partition-key", so all the rows with the same value will go to the same shard. Usually this key is something that is easy to get.
Now, what if we want to get a query that spans all or several shards you ask? Well, some database systems will allow us to do that and they will probably fire parallel queries to separate shards and then will join the results in a single dataset.
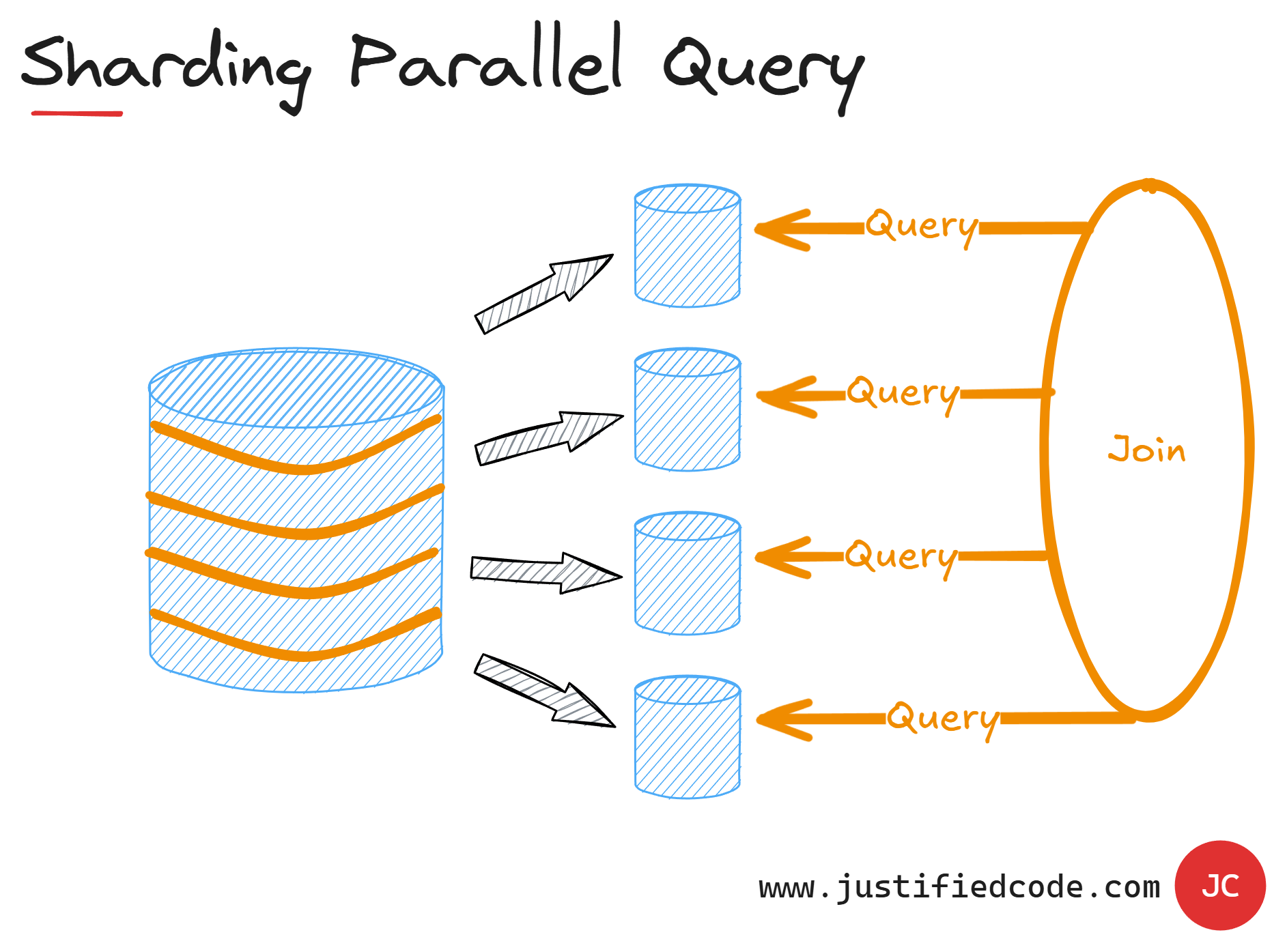
It is like a multi-thread operation that waits for each thread to finish, but if we find ourselves making cross shard queries frequently, maybe our data model needs a revision.
A quick note just to be sure. When we use the partition key, it doesn't mean that each unique value will go to its own shard. It can happen that we'd put many partition keys together in one shard, but a partition key guarantees that the same value of the partition key will go to the same shard.
By relaxing the data consistency and by identifying which data properties are needed for each query, we can optimize for very fast response times. By using carefully planned partition keys, we also ensure fast response times even with the huge data structures.
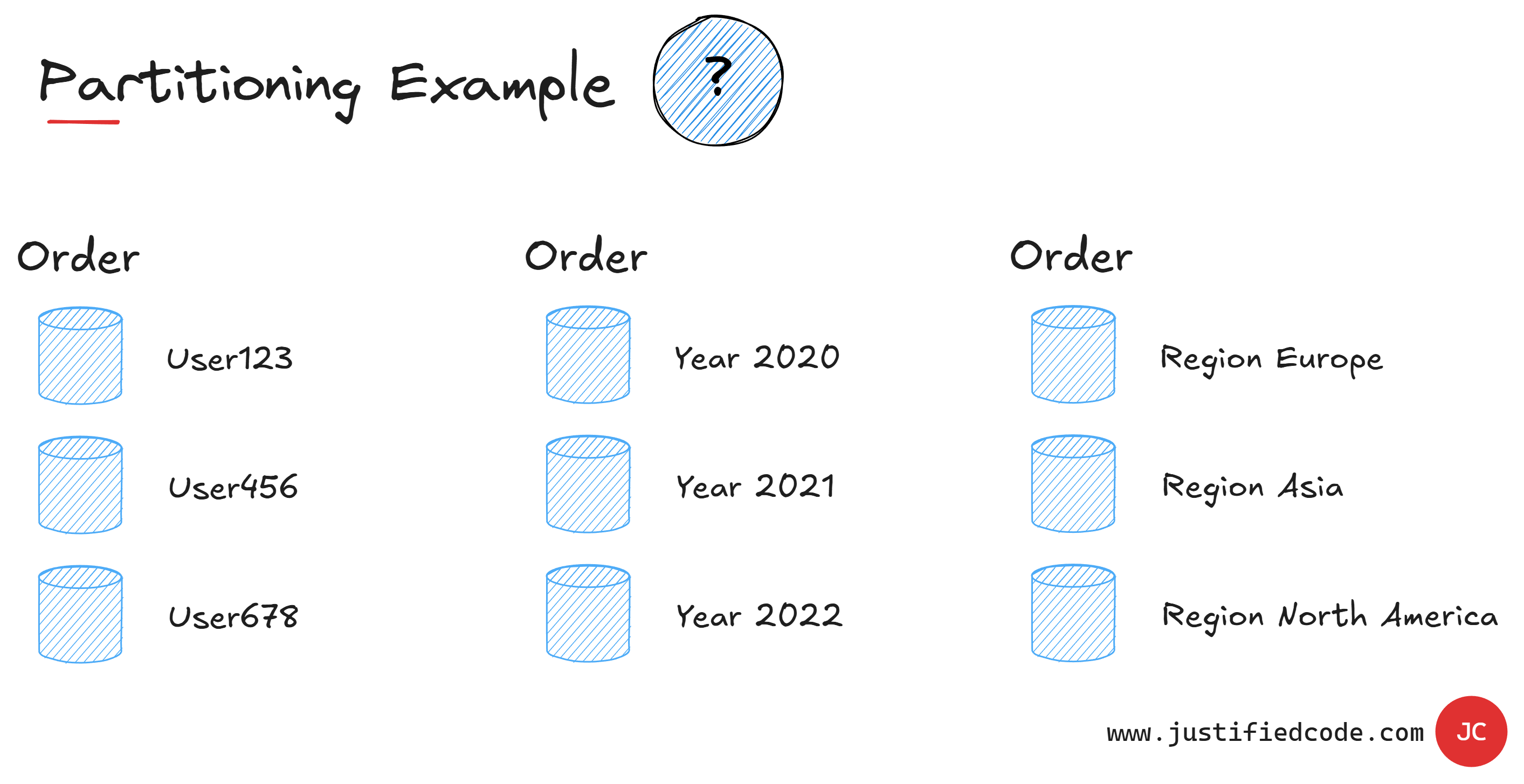
You see from the example above, there is no silver bullet when it comes to choosing partition keys. There isn't a single recipe for all applications. Each application has unique data requirements and it's our job to identify them and make our data storage efficient.
Next Steps
In the next article, we will tackle Caching, a very powerful mechanism to save trips to the data storage.
You don't want to wait? Good. Head to the Web Applications Scalability course where I break all the 5 components of scalability down while annotating every neat diagram with a Pencil, sharing raw experience from the field you won’t find anywhere else.