
- Sep 18, 2025
Scaling Web Apps - Caching
In this article we'll cover the technique of caching, an approach that can help us increase the scalability of our application; however, it introduces additional liabilities such as stale data.
Caching
The principle is easy. Once the data is read from the data storage, it is kept nearby. In future requests, the data is served directly from this near data storage or cache.
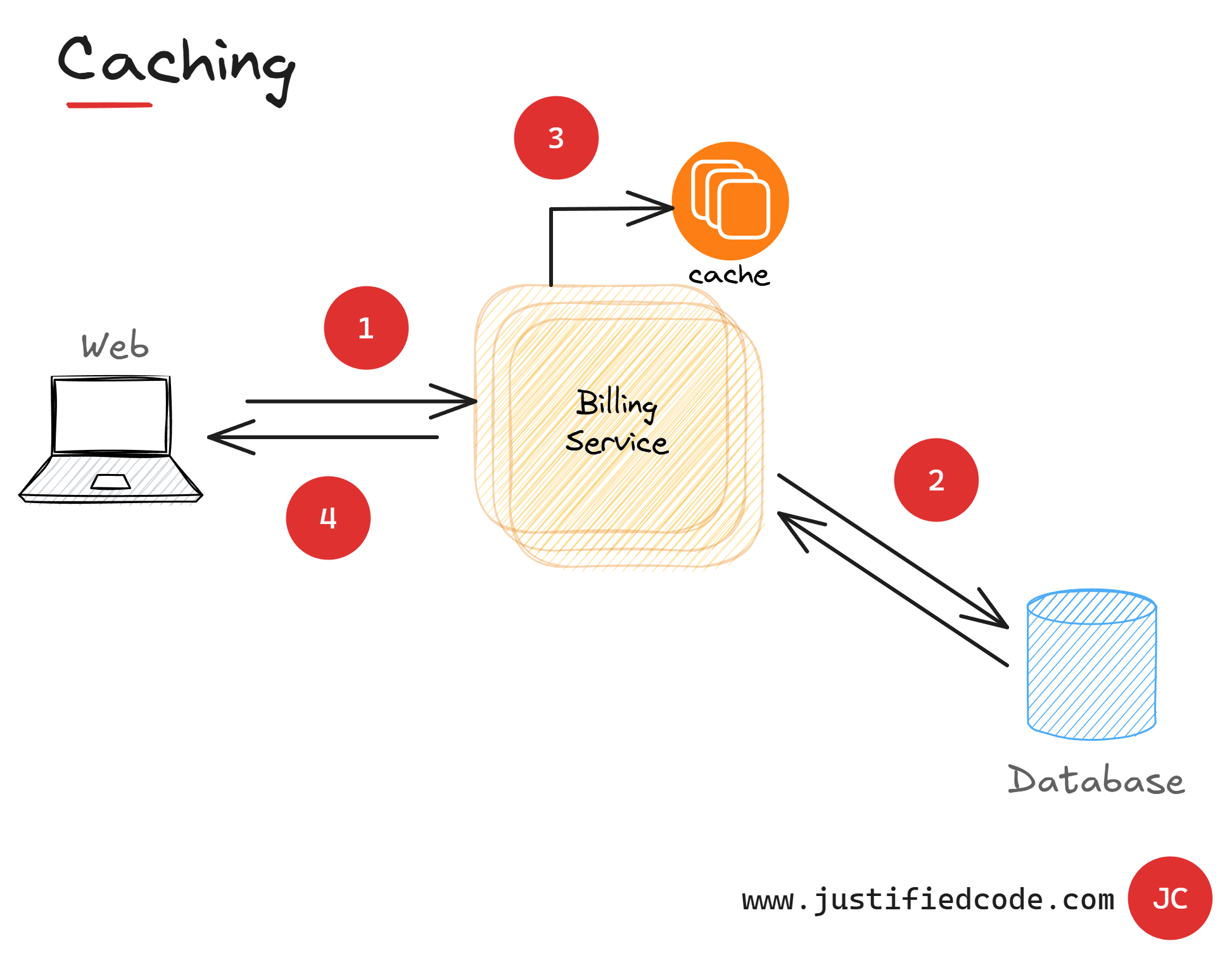
This way the requests only go to the data storage if there is no adequate data in the cache. Effective caching usually avoids many requests to the database, more than 90%.
Caching means saving locally the result of a data storage read from the database and using it as the data source for future requests. The essence of caching is minimizing the amount of work that a database has to do.
Stale Data
The drawback of caching is that of the stale data. Stale data is the data that is no longer reflecting the current state of the database. It is the consequence of storing the previously read data and not going to the data storage every time.
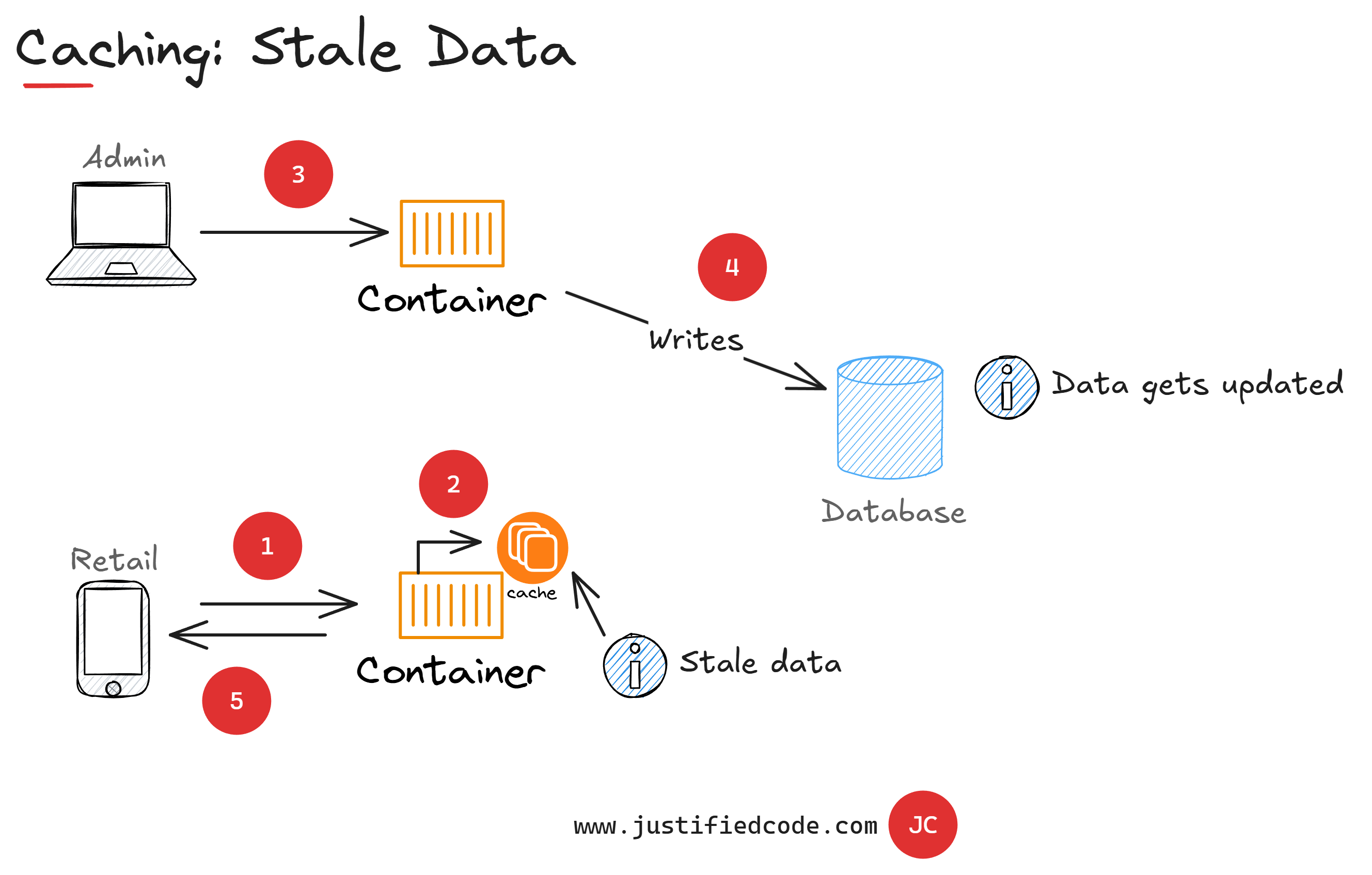
Eventually the data storage will contain fresh, updated information and the cache will contain the previous stale values.
However, stale data is not as bad as it sounds. If you think about it, in a web application the data is always stale, as it always reflects the state of the data when it left the web server. The data in the browser is always in the past, even if that past is just a few milliseconds ago, so stale data is not something inherently bad.
The hard truth is that if you are not building a real-time stocks trading application, stale data is acceptable enough as a cost for having a high scalable architecture.
Expiration Time
You can cope with stale data by adjusting cache expiration time. Expiration time is the lifetime of a cached item. When a cached item expires, it is removed from the cache. The next data query goes to the data storage and probably is written back to the cache with fresh data.
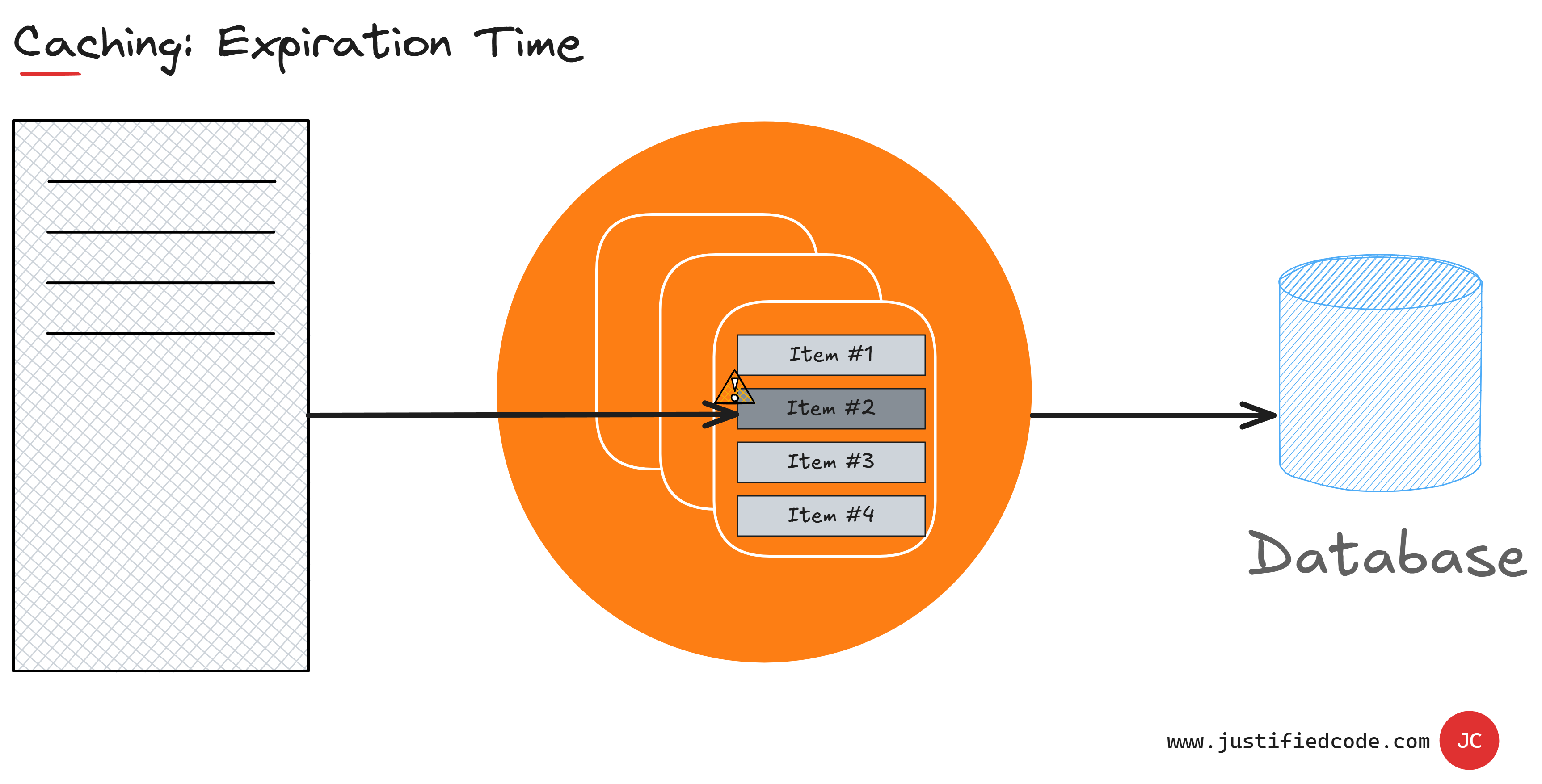
The expiration time has to be long enough for the cache to provide value by saving repeated data access operations, but short enough to minimize data staleness. There is no single recipe for optimal cache expiration time. You will have to experiment, observe the results, and adjust accordingly.
Cache expiration time can be different for different data in our application, being longest for most static data and very short for the data that is frequently updated.
Local Cache
The most basic caching mechanism is using a local cache. A local cache is a cache mechanism that is local to each single application instance. It means that a content of that cache is updated and read by just that application instance, so any changes done to the data by other application instances won't be visible and they may cause stale data and inconsistent results.
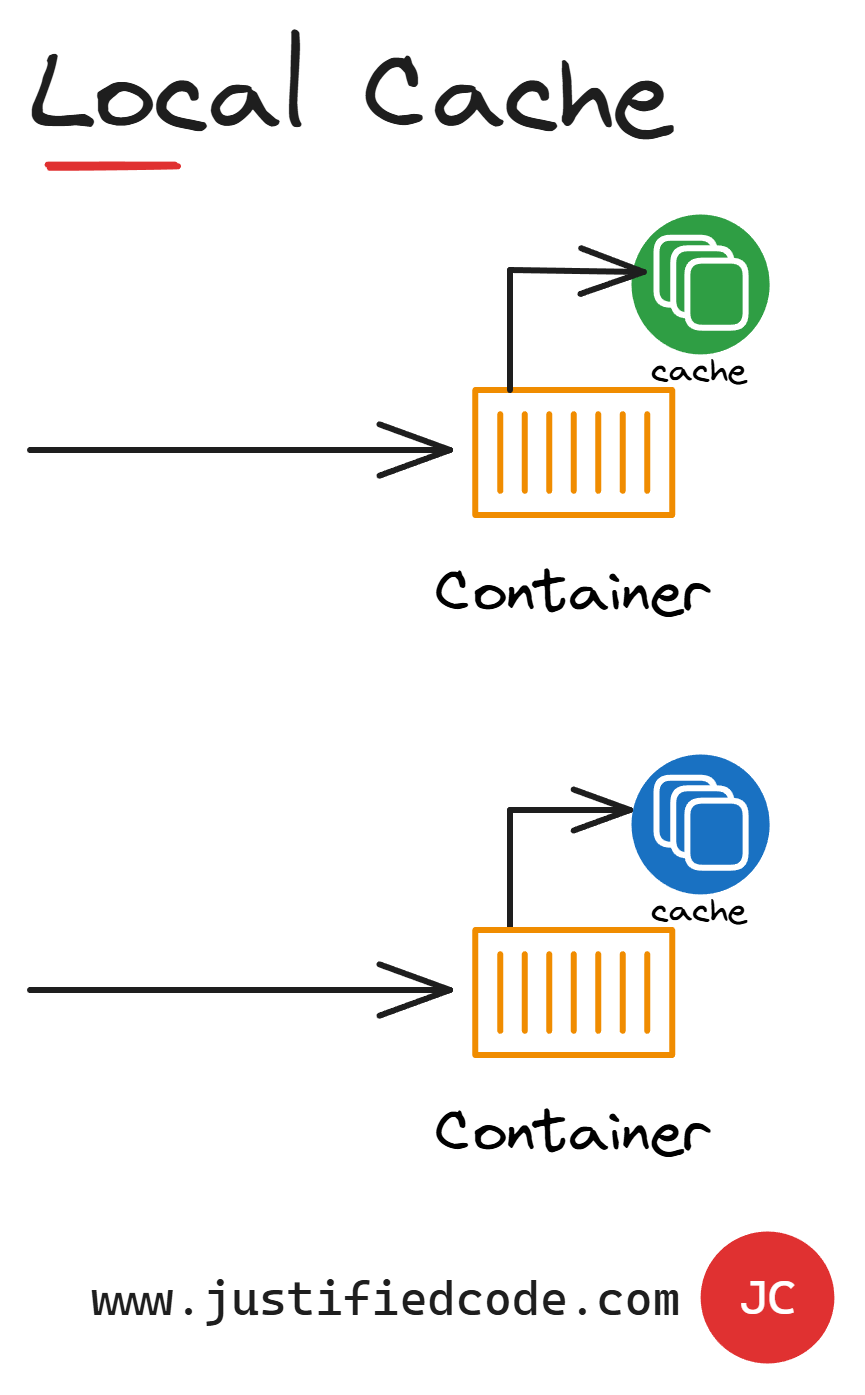
If that's the case, you may ask why even consider using local caching in a highly scalable application? The answer is that local caching still has a place in our architecture because of its speed.
It's the fastest cache available to us. We should locally cache data that is frequently accessed and rarely updated. For example, a product category list, country list, shipping option list, and so on, are the data that are read from the database once and used many times, as they are updated at best, every few months.
By putting them in a local cache, we save the application from making repeated database requests.
Distributed Cache
Traditionally, developers have used caching for only static or fairly static data, meaning data that never changes throughout the life of the application, but that data is usually a very small subset, maybe 10% of all the data in our application.
The local cache is the perfect place for this static-like data, but the real value comes if you can cache dynamic or transactional data, data that keeps changing every few minutes.
You still cache it because within that time span you might fetch it tens of times and save that many trips to the database. If you multiply that by thousands of users who are trying to perform operations simultaneously, you can imagine how many fewer reads you have on the database; however, dynamic data is a challenge in a scalable architecture.
Local caches are unsuitable for dynamic data as each application instance has a separate cache. This is where a distributed cache makes sense.
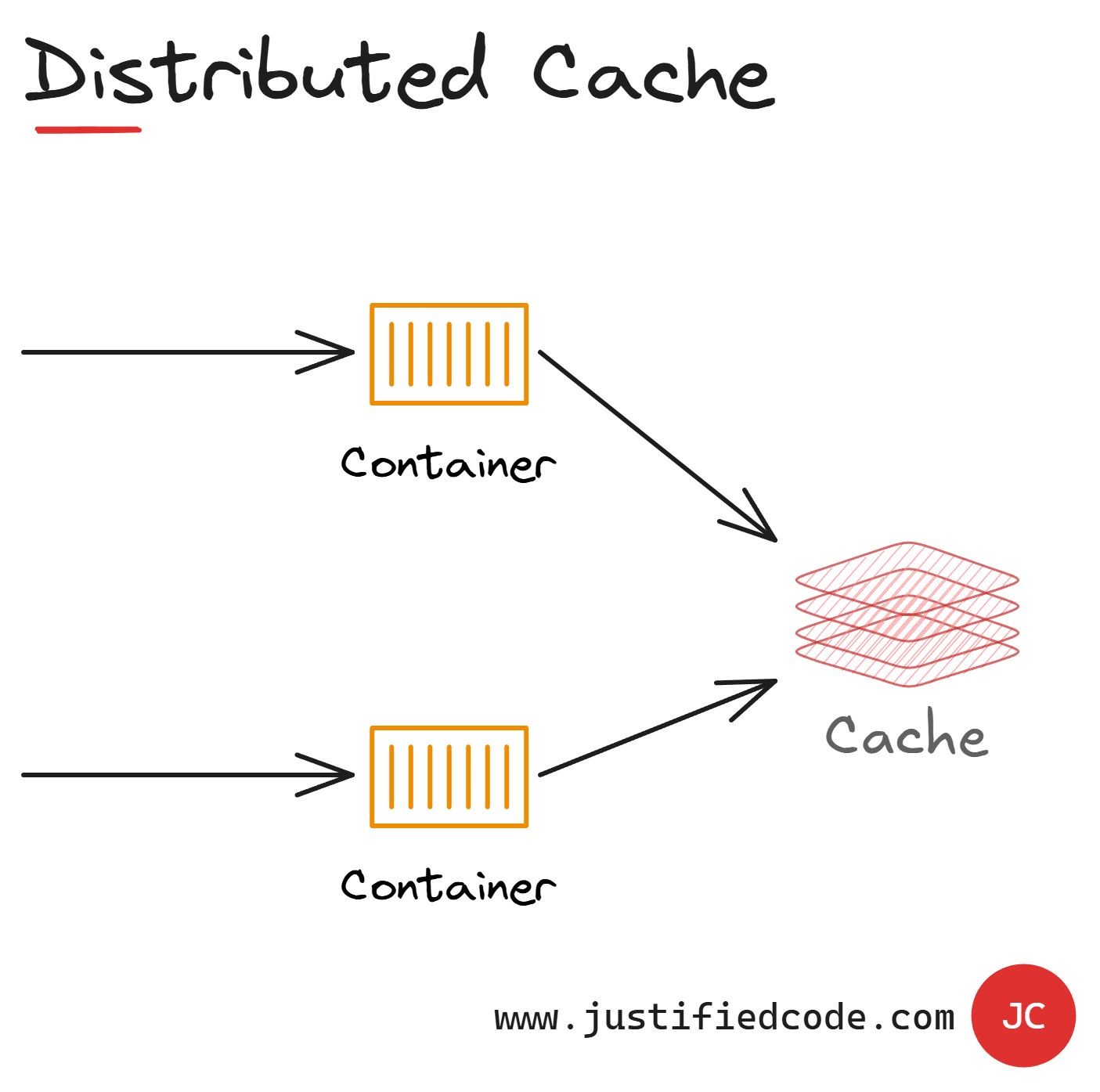
A distributed or shared cache ensures that different application instances (containers) see the same view of a cache data by locating the cache in a separate location over the network.
All the application instances point to the same cache and consequently have access to all the same cache data. This solves the problem of stale data in local caches.
An important side benefit using of distributed caching is the scalability it can provide. Many distributed cache services are implemented using a cluster of services and they use software that distributes the data across a cluster in a transparent manner.
An application instance simply sends a request to the cache service and the underlying infrastructure is responsible for determining the location of the cache data in the cluster. You can easily scale the cache by adding more servers, enhancing the solution resiliency and availability.
The downside of the distributed caching is that the cache is slower to access because it is no longer held in the memory of each application instance. While certainly slower than a local cache, it is still very fast compared to the database access.
Next Steps
We've learned how cache is a simple, but very powerful mechanism to save trips to the data storage. We've seen how stale data is a byproduct of the caching mechanism and it has to be planned for in the application architecture.
In the next article we will tackle the topic of asynchrony and how it influences scalability. In case you don't want to wait, head to the Web Applications Scalability course where I break all the 5 components of scalability down while annotating every neat diagram with my iPad Pencil, sharing raw experience from the field you won’t find anywhere else.