
- Jun 5, 2025
Serving Mobile Apps Labels from Google Cloud Storage
In the old setup, every mobile app launch pinged our backend to fetch UI labels. Our iOS/Android apps called the client’s servers (and a relational DB) on startup just to get public static text.
That worked… until the bills and bottlenecks piled up.
What went wrong?
We saw huge egress and storage costs from pushing the same JSON to every device.
A single relational DB became a performance choke point as our user base grew.
We tried a distributed cache layer (master/slave Redis, invalidation rules, the whole circus) just to keep up—and it was a headache to maintain.
Worst of all, our own servers were only 99.5% reliable (about 4 hours of downtime a month!).
Egress/Storage Costs: Every app start streamed the same JSON from our origin, racking up bandwidth fees.
Scalability: A single SQL DB was ill-suited to serve thousands of JSON reads per second.
Complex Caching: Sharding Redis, invalidating stale entries, managing replicas… it was heavy lift for simple text.
Lower Availability: On-prem infra with 99.5% SLA (≈44 min/week downtime) meant frequent blips.
A Better Way: Static JSON on Google Cloud Storage
We flipped the model: our labels are now just static JSON files in a GCS bucket, served public-read.
On launch, the app does a simple GET to Cloud Storage – no DB call. The Cloud Storage Standard (hot) tier is built to serve frequent reads for mobile apps.
Behind the scenes, Google caches publicly readable objects in its global network, so our JSON gets CDN-like performance.
That means practically infinite scalability and ultra-low latency. Plus, Cloud Storage is cheap. Bandwidth charges for public content are much lower than self-hosted egress.
In short, we offload static assets to GCS and let Google handle the heavy lifting.
Static JSON in GCS: We store each language’s labels as a JSON file in a public bucket.
App Fetches Directly: On startup, iOS/Android simply GET the JSON from GCS; no backend involved.
Built for Mobile: Cloud Storage’s standard tier targets “hot” data (web/mobile apps) .
Scalable & Cheap: GCS auto-scales worldwide, caches content globally, and costs less bandwidth than serving from our own servers.
How we kept the content in sync?
How do our editors’ changes reach that JSON file? We set up a lightweight pipeline.
When a content change happens in the CMS and its database, the CMS publishes the new labels JSON to a message broker. Worker services listen on that queue and, when they see the update, upload the JSON file to the Cloud Storage bucket.
Now the next time the app launches, it fetches the fresh file. In practice the flow is simple:
CMS Update: An editor changes a label in the CMS (writes to the CMS DB).
Publish to Broker: The CMS pushes the new JSON payload into a message queue.
Worker Upload: A worker service reads from the queue and writes the JSON file into GCS.
App Fetch: The mobile app, on next launch, GETs the updated JSON from Cloud Storage.
This async pipeline means the app never “calls home” for labels – it just reads the static file. And because updates are event-driven, the sync happens automatically whenever content changes, without manual intervention.
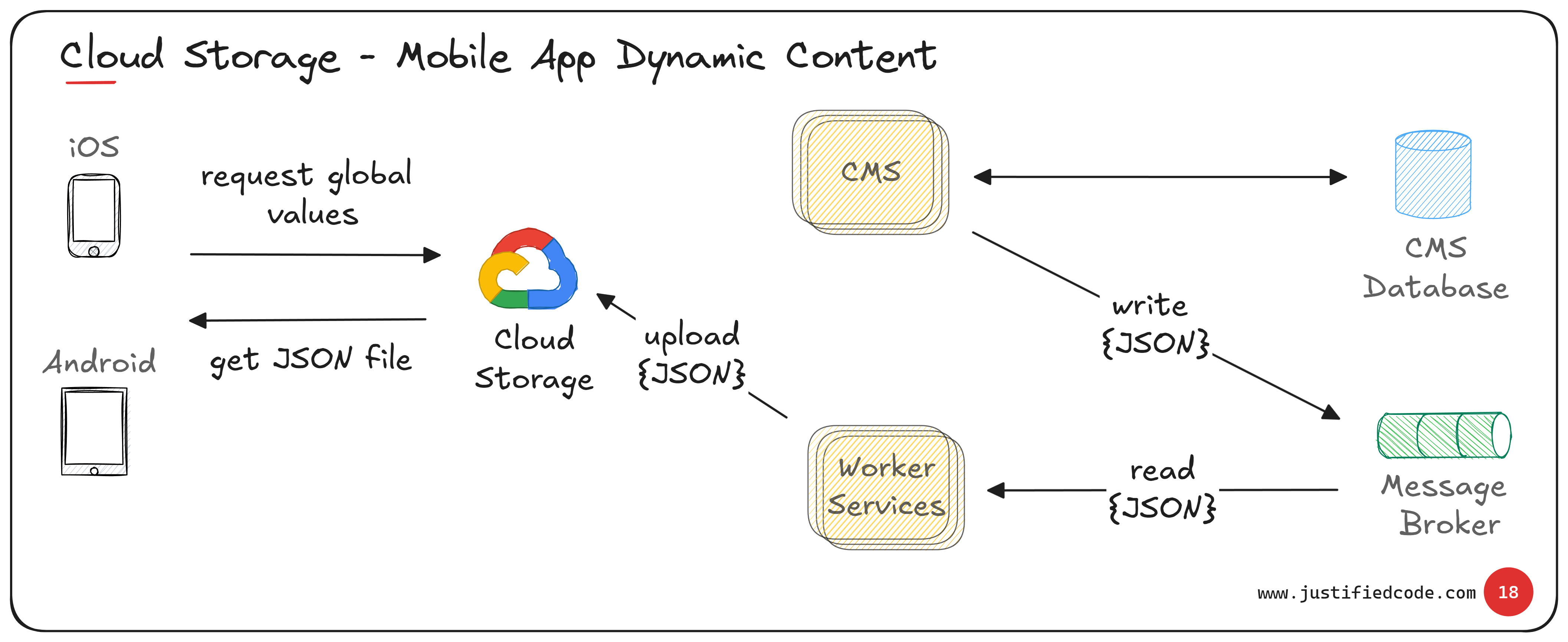
The diagram above ties it together. On the left, iOS/Android apps make a simple request to the Google Cloud Storage bucket (“get JSON file”) and receive the labels JSON in response.
On the right, whenever the CMS and its database are updated, the CMS writes the JSON payload into the message broker. The worker services read from the broker and upload the JSON to the same Cloud Storage bucket.
In effect, mobile apps and editors meet at GCS. The app side is dumb-fast (just HTTP GET a file) and the CMS side pushes updates in the background.
The new way Trade-Offs
Every architecture decision has consequences. This design choice has a few risks to watch for:
Missing Data: The system is eventually consistent. If the CMS fails to publish an update or a worker errors out, the JSON in storage won’t refresh. In that case, apps will keep showing old labels until the next successful update.
Permissions Oops: We rely on the bucket being publicly readable. Proper bucket IAM policies are crucial. Someone could change our JSON causing a damage to the company image.
Sync Pipeline Failures: If the message broker is down or the worker service crashes, no new JSON will upload. Monitoring and retries are needed so the pipeline doesn’t silently die.
Content Errors: If the JSON has a syntax error or missing fields, the app crashes.
In a Nutshell
This new architecture pays off handily:
Lower Cost: We eliminated all the egress from our origin servers. Cloud Storage is cheap (plus generous free quotas). No more hefty network bills.
Higher Uptime: Google guarantees 99.9–99.95% uptime on multi-region buckets , far better than our 99.5%. In practical terms, that’s minutes of downtime per year instead of hours.
Global Performance: Content is served from GCP’s edge caches worldwide, so users anywhere load labels in milliseconds.
Simplicity works better. We ripped out the entire cache-and-DB lookup system. The code on the app side is trivial (fetch file, parse JSON).
Related Materials
Get exclusive deep dives, private notes, behind-the-scenes thinking, and raw experience from the field. Exclusive insights from the mind of a pragmatic architect.